介绍 Gateway API 推理扩展
现代生成式 AI 和大语言模型(LLM)服务在 Kubernetes 上带来独特的流量路由挑战。 与典型的短生命期的无状态 Web 请求不同,LLM 推理会话通常是长时间运行的、资源密集型的,并且具有一定的状态性。 例如,单个由 GPU 支撑的模型服务器可能会保持多个推理会话处于活跃状态,并保留内存中的令牌缓存。
传统的负载均衡器注重 HTTP 路径或轮询,缺乏处理这类工作负载所需的专业能力。 传统的负载均衡器通常无法识别模型身份或请求重要性(例如交互式聊天与批处理任务的区别)。 各个组织往往拼凑出临时解决方案,但一直缺乏标准化的做法。
Gateway API 推理扩展
Gateway API 推理扩展正是为了填补这一空白而创建的, 它基于已有的 Gateway API 进行构建, 添加了特定于推理的路由能力,同时保留了 Gateway 与 HTTPRoute 的熟悉模型。 通过为现有 Gateway 添加推理扩展,你就能将其转变为一个推理网关(Inference Gateway), 从而以“模型即服务”的理念自托管 GenAI/LLM 应用。
此项目的目标是在整个生态系统中改进并标准化对推理工作负载的路由。 关键目标包括实现模型感知路由、支持逐个请求的重要性区分、促进安全的模型发布, 以及基于实时模型指标来优化负载均衡。为了实现这些目标,此项目希望降低延迟并提高 AI 负载中的加速器(如 GPU)利用率。
工作原理
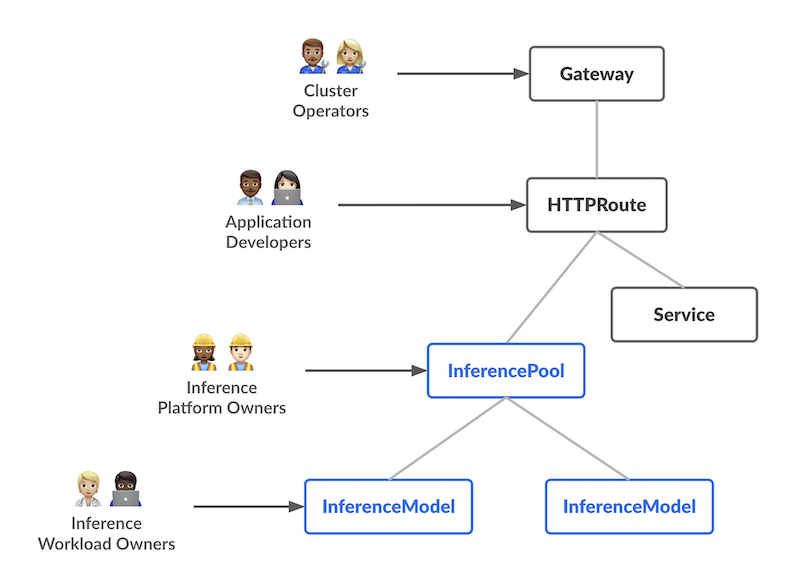
功能设计时引入了两个具有不同职责的全新定制资源(CRD),每个 CRD 对应 AI/ML 服务流程中的一个特定用户角色:
-
InferencePool 定义了一组在共享计算资源(如 GPU 节点)上运行的 Pod(模型服务器)。 平台管理员可以配置这些 Pod 的部署、扩缩容和负载均衡策略。 InferencePool 确保资源使用情况的一致性,并执行平台级的策略。 InferencePool 类似于 Service,但专为 AI/ML 推理服务定制,能够感知模型服务协议。
-
InferenceModel 是面向用户的模型端点,由 AI/ML 拥有者管理。 它将一个公共名称(如 "gpt-4-chat")映射到 InferencePool 内的实际模型。 这使得负载拥有者可以指定要服务的模型(及可选的微调版本),并配置流量拆分或优先级策略。
简而言之,InferenceModel API 让 AI/ML 拥有者管理“提供什么服务”,而 InferencePool 则让平台运维人员管理“在哪儿以及如何提供服务”。
请求流程
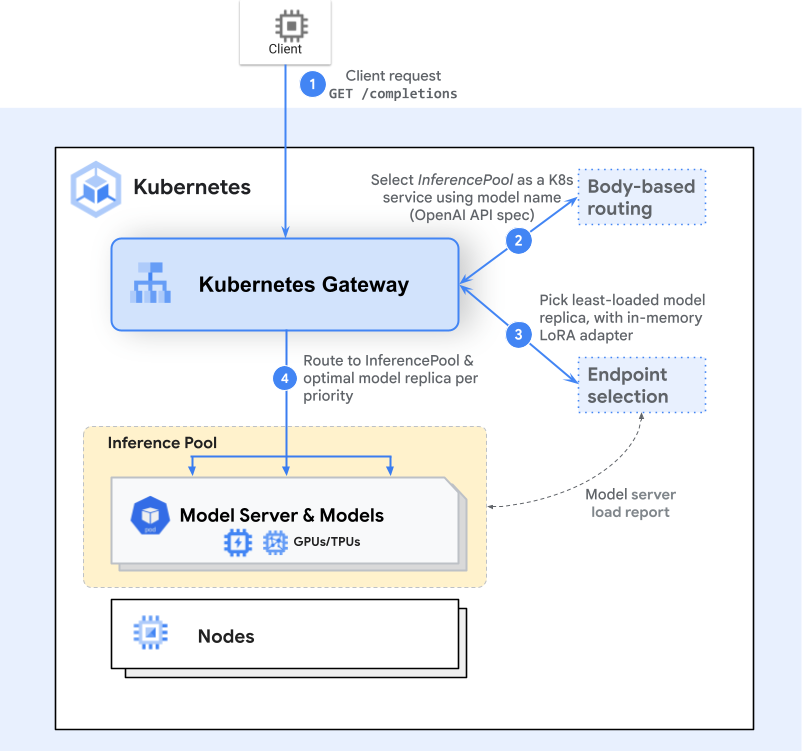
请求的处理流程基于 Gateway API 模型(Gateway 和 HTTPRoute),在其中插入一个或多个对推理有感知的步骤(扩展)。 以下是一个使用端点选择扩展(Endpoint Selection Extension, ESE) 的高级请求流程示意图:
-
Gateway 路由
客户端发送请求(例如向
/completions发起 HTTP POST)。 Gateway(如 Envoy)会检查 HTTPRoute,并识别出匹配的 InferencePool 后端。 -
端点选择
Gateway 不会简单地将请求转发到任一可用的 Pod, 而是调用一个特定于推理的路由扩展(端点选择扩展)从多个可用 Pod 中选出最优者。 此扩展根据实时 Pod 指标(如队列长度、内存使用量、加载的适配器等)来选择最适合请求的 Pod。
-
推理感知调度
所选 Pod 是基于用户重要性或资源需求下延迟最低或效率最高者。 随后 Gateway 将流量转发到这个特定的 Pod。
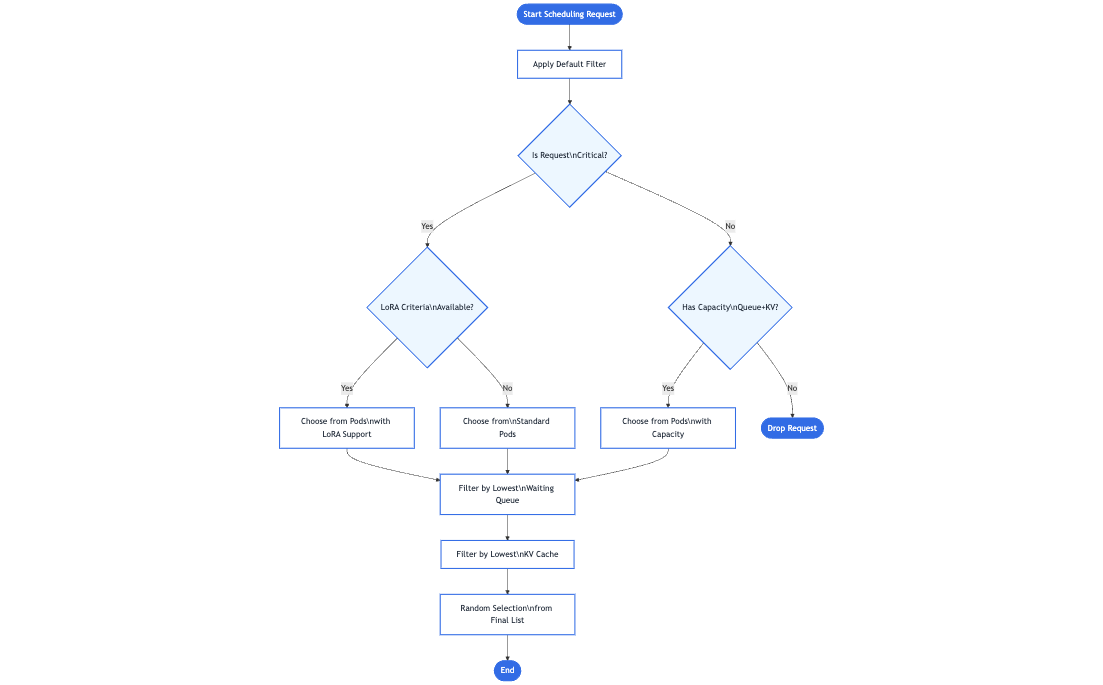
这一额外步骤提供了一种更为智能的模型感知路由机制,但对于客户端来说感觉就像一个普通的请求。 此外,这种设计具有良好的可扩展性,任何推理网关都可以通过添加新的特定于推理的扩展来处理新的路由策略、高级调度逻辑或特定硬件需求。 随着此项目的持续发展,欢迎社区贡献者开发与底层 Gateway API 模型完全兼容的新扩展,进一步拓展高效、智能的 GenAI/LLM 路由能力。
基准测试
我们将此扩展与标准 Kubernetes Service 进行了对比测试,基于 vLLM 部署模型服务。 测试环境是在 Kubernetes 集群中运行 vLLM(v1) 的多个 H100(80 GB)GPU Pod,并部署了 10 个 Llama2 模型副本。 本次测试使用了 Latency Profile Generator (LPG) 工具生成流量,测量吞吐量、延迟等指标。采用的工作负载数据集为 ShareGPT, 流量从 100 QPS 提升到 1000 QPS。
主要结果
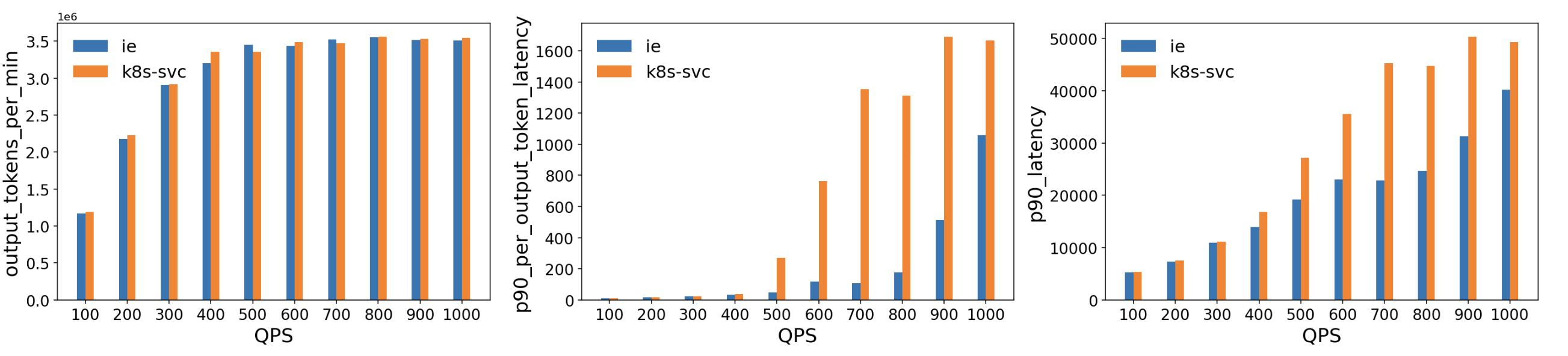
- 吞吐量相当:在整个测试的 QPS 范围内,ESE 达到的吞吐量基本与标准 Kubernetes Service 持平。
- 延迟更低:
- 输出令牌层面的延迟:在高负载(QPS 500 以上)时,ESE 显示了 p90 延迟明显更低, 这表明随着 GPU 显存达到饱和,其模型感知路由决策可以减少排队等待和资源争用。
- 整体 p90 延迟:出现类似趋势,ESE 相比基线降低了端到端尾部延迟,特别是在 QPS 超过 400–500 时更明显。
这些结果表明,此扩展的模型感知路由显著降低了 GPU 支撑的 LLM 负载的延迟。 此扩展通过动态选择负载最轻或性能最优的模型服务器,避免了传统负载均衡方法在处理较大的、长时间运行的推理请求时会出现的热点问题。
路线图
随着 Gateway API 推理扩展迈向 GA(正式发布),计划中的特性包括:
- 前缀缓存感知负载均衡以支持远程缓存
- LoRA 适配器流水线方便自动化上线
- 同一重要性等级下负载之间的公平性和优先级
- HPA 支持基于聚合的模型层面指标扩缩容
- 支持大规模多模态输入/输出
- 支持额外的模型类型(如扩散模型)
- 异构加速器(支持多个加速器类型,并具备延迟和成本感知的负载均衡)
- 解耦式服务架构,以独立扩缩资源池
总结
通过将模型服务对齐到 Kubernetes 原生工具链,Gateway API 推理扩展致力于简化并标准化 AI/ML 流量的路由方式。 此扩展引入模型感知路由、基于重要性的优先级等能力,帮助运维团队平滑高效地将合适的 LLM 服务交付给合适的用户。